- Random Forest Hyperparameter Tuning in Python
- Random Forest Hyperparameters
- 1. n_estimators
- 2. max_features
- 3. max_depth
- 4. max_leaf_nodes
- 5. max_sample
- 6. min_sample_split
- Random Forest Hyperparameter Tuning in Python using Sklearn
- Случайный лес python sklearn
- Порядок действий в алгоритме
- Теоретическая составляющая алгоритма случайного дерева
- Реализация алгоритма Random Forest
- Недостатки алгоритма
- Заключение
Random Forest Hyperparameter Tuning in Python
In this article, we shall implement Random Forest Hyperparameter Tuning in Python using Sci-kit Library.
Sci-kit aka Sklearn is a Machine Learning library that supports many Machine Learning Algorithms, Pre-processing Techniques, Performance Evaluation metrics, and many other algorithms. Ensemble Techniques are considered to give a good accuracy score among all the Machine Learning Algorithms. Since Machine Learning are classified into Supervised and Unsupervised Learning, we have two types of approach in Supervised Learning that is Regression and classification. Talking of Classification, let us consider one of the ensembles technique i.e., the Random Forest algorithm. While building a Classification model, we always think about what value should be assigned to the Hyperparameters. Hyperparameters are similar to parameters but the only difference is there is no one specific value to these Hyperparameters.
Since we are talking about Random Forest Hyperparameters, let us see what different Hyperparameters can be Tuned.
Random Forest Hyperparameters
1. n_estimators
Random Forest is nothing but a set of trees. It is an extended version of the Decision Tree in a very optimized way. One issue here might arise is how many trees need to be created. n_estimator is the hyperparameter that defines the number of trees to be used in the model. The tree can also be understood as the sub-divisions.
By default: n_estimators=100
2. max_features
In order to train the Machine learning model, the given dataset should contain multiple features/variables to predict the label/target. Max_features limits a count to select the maximum features in each tree.
By default: max_features="sqrt" [available: ["sqrt", "log2", None>]
3. max_depth
A tree is incomplete without a split or child node. max_depth determines the maximum number of splits each tree can take. If the max_depth is too low, the model will be trained less and have a high bias, leading the model to underfit. In the same way, if the max_depth is high, the model learns too much and leads to high variance, leading the model to overfit.
4. max_leaf_nodes
We have a tree and know what max_depth is used for. Talking of a Tree, each tree is used to split into multiple nodes. But how many divisions of nodes should be done is specified by max_lead_nodes. max_leaf_nodes restricts the growth of each tree.
By default: max_leaf_nodes = None; (takes an unlimited number of nodes)
5. max_sample
Apart from the features, we have a large set of training datasets. max_sample determines how much of the dataset is given to each individual tree.
By default: max_sample = None; (this means data.shape[0] is taken)
6. min_sample_split
Since ensemble algorithms are weak learners and are derived from strong learners, Random Forest which is a Weak Learner depends on Decision Tree decisions. min_sample_split determines the minimum number of decision tree observations in any given node in order to split.
By default: min_sample_split = 2 (this means every node has 2 subnodes)
For a more detailed article, you can check this: Hyperparameters of Random Forest Classifier
Random Forest Hyperparameter Tuning in Python using Sklearn
Sklearn supports Hyperparameter Tuning algorithms that help to fine-tune the Machine learning models. In this article, we shall use two different Hyperparameter Tuning i.e., GridSearchCV and RandomizedSearchCV.
Import the required modules that are needed to fine-tune the Hyperparameters in Random Forest.
Источник
Случайный лес python sklearn

Здесь мы на основе классификации просто добавляем метод для отбора признаков.
Порядок действий в алгоритме
- Загрузите ваши данные.
- В заданном наборе данных определите случайную выборку.
- Далее алгоритм построит по выборке дерево решений.
- Дерево строится, пока в каждом листе не более n объектов, или пока не будет достигнута определенная высота.
- Затем будет получен результат прогнозирования из каждого дерева решений.
- На этом этапе голосование будет проводиться для каждого прогнозируемого результата: мы выбираем лучший признак, делаем разбиение в дереве по нему и повторяем этот пункт до исчерпания выборки.
- В конце выбирается результат прогноза с наибольшим количеством голосов. Это и есть окончательный результат прогнозирования.
Теоретическая составляющая алгоритма случайного дерева
По сравнению с другими методами машинного обучения, теоретическая часть алгоритма Random Forest проста. У нас нет большого объема теории, необходима только формула итогового классификатора a(x) :
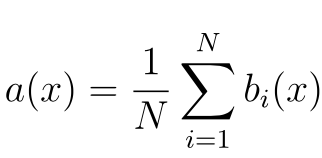
- N – количество деревьев;
- i – счетчик для деревьев;
- b – решающее дерево;
- x – сгенерированная нами на основе данных выборка.
Стоит также отметить, что для задачи классификации мы выбираем решение голосованием по большинству, а в задаче регрессии – средним.
Реализация алгоритма Random Forest
Реализуем алгоритм на простом примере для задачи классификации, используя библиотеку scikit-learn:

- Имеет высокую точность предсказания, которая сравнима с результатами градиентного бустинга.
- Не требует тщательной настройки параметров, хорошо работает из коробки.
- Практически не чувствителен к выбросам в данных из-за случайного семплирования (random sample).
- Не чувствителен к масштабированию и к другим монотонным преобразованиям значений признаков.
- Редко переобучается. На практике добавление деревьев только улучшает композицию.
- В случае наличия проблемы переобучения, она преодолевается путем усреднения или объединения результатов различных деревьев решений.
- Способен эффективно обрабатывать данные с большим числом признаков и классов.
- Хорошо работает с пропущенными данными – сохраняет хорошую точность даже при их наличии.
- Одинаково хорошо обрабатывает как непрерывные, так и дискретные признаки
- Высокая параллелизуемость и масштабируемость.
Недостатки алгоритма

- Для реализации алгоритма случайного дерева требуется значительный объем вычислительных ресурсов.
- Большой размер моделей.
- Построение случайного леса отнимает больше времени, чем деревья решений или линейные алгоритмы.
- Алгоритм склонен к переобучению на зашумленных данных.
- Нет формальных выводов, таких как p-values, которые используются для оценки важности переменных.
- В отличие от более простых алгоритмов, результаты случайного леса сложнее интерпретировать.
- Когда в выборке очень много разреженных признаков, таких как тексты или наборы слов (bag of words), алгоритм работает хуже чем линейные методы.
- В отличие от линейной регрессии, Random Forest не обладает возможностью экстраполяции. Это можно считать и плюсом, так как в случае выбросов не будет экстремальных значений.
- Если данные содержат группы признаков с корреляцией, которые имеют схожую значимость для меток, то предпочтение отдается небольшим группам перед большими, что ведет к недообучению.
- Процесс прогнозирования с использованием случайных лесов очень трудоемкий по сравнению с другими алгоритмами.
Заключение
Метод случайного дерева (Random Forest) – это универсальный алгоритм машинного обучения с учителем. Его можно использовать во множестве задач, но в основном он применяется в проблемах классификации и регрессии.
Действенный и простой в понимании, алгоритм имеет значительный недостаток – заметное замедление работы при определенной настройке параметров внутри него.
Вы можете использовать случайный лес, если вам нужны чрезвычайно точные результаты или у вас есть огромный объем данных для обработки, и вам нужен достаточно сильный алгоритм, который позволит вам эффективно обработать все данные.
Дополнительные материалы:
Источник