- Алгоритмы классификации – случайный лес
- Работа алгоритма случайного леса
- Реализация в Python
- Выход
- Плюсы и минусы случайного леса
- Pros
- Cons
- Дерево решений и случайный лес
- Древо решений:
- Типы узлов в дереве решений:
- Важная терминология:
- Теперь давайте посмотрим, как этот алгоритм применяется машиной:
- Случайный лес:
- Случайный лес в основном использует две техники.
- Алгоритм для случайного леса:
- Когда выбрать дерево решений или случайный лес?
Алгоритмы классификации – случайный лес
Случайный лес – это контролируемый алгоритм обучения, который используется как для классификации, так и для регрессии. Но, тем не менее, он в основном используется для задач классификации. Поскольку мы знаем, что лес составлен из деревьев, и больше деревьев означает более устойчивый лес. Точно так же алгоритм случайного леса создает деревья решений для выборок данных, а затем получает прогноз по каждой из них и, наконец, выбирает лучшее решение посредством голосования. Это метод ансамбля, который лучше, чем единое дерево решений, потому что он уменьшает переобучение путем усреднения результата.
Работа алгоритма случайного леса
Мы можем понять работу алгоритма Random Forest с помощью следующих шагов:
- Шаг 1 – Сначала начните с выбора случайных выборок из заданного набора данных.
- Шаг 2 – Далее этот алгоритм построит дерево решений для каждой выборки. Затем он получит результат прогнозирования из каждого дерева решений.
- Шаг 3 – На этом этапе голосование будет проводиться для каждого прогнозируемого результата.
- Шаг 4 – Наконец, выберите результат прогноза с наибольшим количеством голосов в качестве окончательного результата прогноза.
Шаг 1 – Сначала начните с выбора случайных выборок из заданного набора данных.
Шаг 2 – Далее этот алгоритм построит дерево решений для каждой выборки. Затем он получит результат прогнозирования из каждого дерева решений.
Шаг 3 – На этом этапе голосование будет проводиться для каждого прогнозируемого результата.
Шаг 4 – Наконец, выберите результат прогноза с наибольшим количеством голосов в качестве окончательного результата прогноза.
Следующая диаграмма проиллюстрирует его работу –
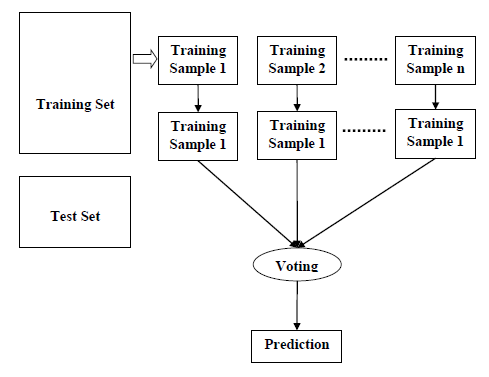
Реализация в Python
Во-первых, начните с импорта необходимых пакетов Python –
import numpy as np import matplotlib.pyplot as plt import pandas as pd
Затем загрузите набор данных iris с веб-ссылки следующим образом:
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
Далее нам нужно назначить имена столбцов для набора данных следующим образом:
headernames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
Теперь нам нужно прочитать набор данных в pandas dataframe следующим образом:
dataset = pd.read_csv(path, names = headernames) dataset.head()
| чашелистник длины | чашелистник ширины | Лепесток длина | Лепесток ширины | Учебный класс | |
|---|---|---|---|---|---|
| 0 | 5,1 | 3,5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4,9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4,7 | 3,2 | 1,3 | 0.2 | Iris-setosa |
| 3 | 4,6 | 3,1 | 1,5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3,6 | 1.4 | 0.2 | Iris-setosa |
Предварительная обработка данных будет выполняться с помощью следующих строк сценария.
X = dataset.iloc[:, :-1].values y = dataset.iloc[:, 4].values
Далее, мы разделим данные на разделение на поезда и тесты. Следующий код разделит набор данных на 70% данных обучения и 30% данных тестирования.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.30)
Затем обучаем модель с помощью класса sklearn класса RandomForestClassifier следующим образом –
from sklearn.ensemble import RandomForestClassifier classifier = RandomForestClassifier(n_estimators = 50) classifier.fit(X_train, y_train)
Наконец, нам нужно сделать прогноз. Это можно сделать с помощью следующего скрипта –
y_pred = classifier.predict(X_test)
Затем распечатайте результаты следующим образом –
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score result = confusion_matrix(y_test, y_pred) print("Confusion Matrix:") print(result) result1 = classification_report(y_test, y_pred) print("Classification Report:",) print (result1) result2 = accuracy_score(y_test,y_pred) print("Accuracy:",result2)
Выход
Confusion Matrix: [[14 0 0] [ 0 18 1] [ 0 0 12]] Classification Report: precision recall f1-score support Iris-setosa 1.00 1.00 1.00 14 Iris-versicolor 1.00 0.95 0.97 19 Iris-virginica 0.92 1.00 0.96 12 micro avg 0.98 0.98 0.98 45 macro avg 0.97 0.98 0.98 45 weighted avg 0.98 0.98 0.98 45 Accuracy: 0.9777777777777777
Плюсы и минусы случайного леса
Pros
Ниже приведены преимущества алгоритма Random Forest –
- Он преодолевает проблему переоснащения путем усреднения или объединения результатов различных деревьев решений.
- Случайные леса хорошо работают с большим количеством элементов данных, чем одно дерево решений.
- Случайный лес имеет меньшую дисперсию, чем одно дерево решений.
- Случайные леса очень гибки и обладают очень высокой точностью.
- Масштабирование данных не требует в алгоритме случайного леса. Он сохраняет хорошую точность даже после предоставления данных без масштабирования.
- Алгоритмы Random Forest поддерживают хорошую точность даже при отсутствии значительной части данных.
Он преодолевает проблему переоснащения путем усреднения или объединения результатов различных деревьев решений.
Случайные леса хорошо работают с большим количеством элементов данных, чем одно дерево решений.
Случайный лес имеет меньшую дисперсию, чем одно дерево решений.
Случайные леса очень гибки и обладают очень высокой точностью.
Масштабирование данных не требует в алгоритме случайного леса. Он сохраняет хорошую точность даже после предоставления данных без масштабирования.
Алгоритмы Random Forest поддерживают хорошую точность даже при отсутствии значительной части данных.
Cons
Ниже приведены недостатки алгоритма Random Forest –
Сложность является основным недостатком алгоритмов случайного леса.
Построение Случайных лесов намного сложнее и отнимает больше времени, чем деревья решений.
Для реализации алгоритма Random Forest требуется больше вычислительных ресурсов.
Это менее интуитивно понятно в случае, когда у нас есть большая коллекция деревьев решений.
Процесс прогнозирования с использованием случайных лесов очень трудоемкий по сравнению с другими алгоритмами.
Источник
Дерево решений и случайный лес
Существуют различные алгоритмы машинного обучения, с которыми мы взаимодействуем в повседневной жизни и используем, даже не подозревая об этом. Один из наиболее часто используемых алгоритмов, который один человек использует в своей повседневной жизни, — это дерево решений. Возникает вопрос: как?
Мы, люди, должны принимать сотни решений каждый день, будь то просмотр видео на YouTube, покупка продуктов или размещение заказа на сайте онлайн-покупок. Получаем несколько мыслей и рекомендаций. Мы вкладываем все это в свой разум и наконец принимаем решение. Звучит просто, правда? Теперь давайте разберемся, как решения принимаются алгоритмами машинного обучения, и в чем на самом деле смысл и необходимость.

Древо решений:
Согласно Википедии, «дерево решений — это инструмент поддержки принятия решений, который использует древовидную модель решений и их возможных последствий, включая случайные исходы событий, затраты на ресурсы и полезность. Это один из способов отобразить алгоритм, который содержит только условные управляющие операторы ».
Как правило, дерево решений задает вопрос и на основе ответа классифицирует объект / человека / функцию. Классификация может быть категориальной или числовой. По большей части деревья решений довольно интуитивно понятны для работы; вы начинаете с вершины и спускаетесь вниз, пока не дойдете до точки, где дальше вы не сможете спуститься; вот как вы классифицируете образец.
Давайте рассмотрим пример, чтобы понять, как выглядит дерево решений. Мы должны определить, является ли данное животное Ястребом, Пингвином, Дельфином или Медведем. Итак, мы начинаем с того, есть ли у него перья или нет, если это птица, то это либо ястреб, либо пингвин, а если у нее нет перьев, то это может быть либо дельфин, либо медведь. Теперь, в следующий ход, мы спрашиваем, может он летать или нет, если да, то это ястреб, если нет, то пингвин. С другой стороны, мы спрашиваем, есть ли у него плавники? Если да; это дельфин, если нет, то медведь. Таким образом, формируется простое дерево решений, как показано ниже.
Типы узлов в дереве решений:
⇒ Вершина дерева называется «Корневой узел» или просто «Корень».
⇒ Затем есть «внутренние узлы» или, можно сказать, «узлы принятия решений». У этих узлов есть стрелки, указывающие на них, также указывающие от них. Они показывают, что нужно принять решение.
⇒ Наконец, листовые узлы или только конечные узлы. У них есть стрелки, указывающие на них, но не направленные от них. Они показывают результат пути решения.
Важная терминология:
⇒ Энтропия: она известна как мера случайности, или мы можем сказать, что энтропия используется как способ измерения «смешанности» столбца.
⇒ Прирост информации: это помогает нам понять общую энтропию, которая снизилась после разделения. Его можно рассчитать как (Энтропия до разделения — Взвешенная энтропия после разделения)
⇒ Примесь: это говорит нам о том, насколько данные смешаны в результате. Это помогает проверить однородность
Примечание: чистый узел имеет нулевую энтропию.
Теперь давайте посмотрим, как этот алгоритм применяется машиной:
- Найдите атрибут для первого разветвления.
- Проверьте примесь, выбрав один узел любого объекта.
- Рассчитайте энтропию подузла и получение информации.
- Повторите это для другой функции, чтобы начать процесс.
- Перейдите к разделению подузлов и вычислению энтропии и прироста информации.
- Выберите лучшее из этого рекурсивного разбиения.
Случайный лес:
Как следует из названия; Случайный лес — это набор различных деревьев решений, построенных вместе для большого набора данных. Правильное определение случайного леса согласно Википедии «Случайные леса или леса случайных решений — это метод обучения ансамбля для классификации, регрессии и других задач, которые работают путем построения множества деревьев решений во время обучения и вывода класса, который является режимом классы или средний / средний прогноз отдельных деревьев ».
Случайный лес в основном использует две техники.
а.) Начальная загрузка: когда у нас очень большой набор данных, создание единого дерева решений может не дать хорошего результата. Итак, мы случайным образом выбираем некоторые функции и некоторые наблюдения и составляем N различных деревьев решений с этими случайно выбранными функциями и наблюдениями. Но мы следим за тем, чтобы все особенности и наблюдения были выбраны хотя бы один раз.
б) Бэггинг: этот метод используется, когда мы хотим получить какое-то решение из созданного нами случайного леса. Итак, мы берем несколько n различных деревьев решений; передать наши данные из этих деревьев, а затем получить совокупный результат для принятия решения.

Алгоритм для случайного леса:
(a) взять загрузочную выборку z * размера N из обучающих данных (b) Вырастить случайное дерево леса Tb (рекурсивное повторение для каждого конечного узла) i. выбрать случайным образом m переменную из переменной p ii. Выложите лучшую переменную ноду / точку разделения из m iii. Разделить узел на два дочерних узла
2. Выведите ансамбли деревьев 1 в B
Когда выбрать дерево решений или случайный лес?
Деревья решений можно использовать, когда набор данных сравнительно невелик, например, для больших наборов данных. Для классификации 10 000 000 данных и 10 000 атрибутов требуются часы и дни. В то время как случайный лес можно использовать, когда у нас есть такой большой набор данных, поскольку он разбивает данные на более мелкие части.
⇒ усредняет значения дерева решений
⇒ рассчитывает точную оценку.
Случайные леса иногда трудно интерпретировать, поэтому, если мы хотим, чтобы результат был интерпретируемым, мы должны выбрать дерево решений, поскольку его сравнительно просто интерпретировать.
Источник